形態素解析を既存のどこかが提供しているAPIで利用することは、意外と制約があり、実装が面倒なときがあります。そんな時に気軽に単語の分解程度として使えるものがPHPの以下の関数。
preg_match_all('/[一-龠]+|[ぁ-ん]+|[ァ-ヴー]+|[a-zA-Z0-9]+|[a-zA-Z0-9]+/u', $stc_en, $matches);
[一-龠]は、漢字の連続した文字の場合を表しています。
[ぁ-ん]は、ひらがなを表し、[ァ-ヴー]は、カタカナを表しています。
[a-zA-Z0-9]は、半角英数字の連続した文字。
[a-zA-Z0-9]は、全角英数字の練した文字を表します。
文字の種類の連続を判定するので、日本語だと、助詞や副詞などで正しく単語の分解にはなりませんが、文章の分解としてはそれっぽいものになります。
別途、単語の辞書機能を即席で添えて作れば、自分なりの単語分解システムが作れると思います。
実際、どこかの辞書やエンジンを使っても、固有名詞や専門用語、新語などは、悩まされるのでライトに使うならこれくらいでよいのではないでしょうか。
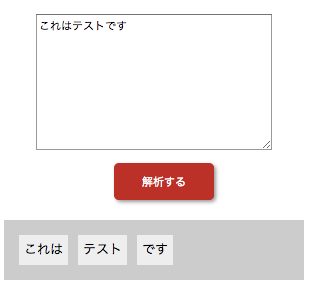
実際フォームで書いて分解するサンプルを作ってみましたのでお試しにどうぞ。